
I’ve been using a service known affectionately to many as HARO for several years now. HARO or Help a Reporter Out started as a Facebook group administered by entrepreneur Peter Shankman (he was [email protected] for context). It was a way for him to connect reporters with reliable sources.
For example, a reporter from Forbes might be researching a story about former attorneys who are now stay at home dads in the Illinois area. Peter would put that query out to the list and anyone who fit the bill could get in touch with the reporter.
It was a brilliant idea that grew by the thousands in short order. So Peter moved everything over to an official newsletter that put out calls for sources three times per day, five days a week. On any given day there might be three hundred requests all in a long text email like you see here.

The challenging aspect for people looking to get a mention in a news story or feature piece, was that a request, which may be a good fit, could only appear once every three days. But the prospective source would be obliged to check through the entire list regularly for FOMO (fear of missing out). While it’s brilliant from a business perspective, it is not the best return on investment for your time.
For years, I’ve seen numerous attempts to outsource HARO. People hired virtual assistants to look for various keywords, identify good prospects, even reach out to the reporter on their client’s behalf. However, if the VA researched the emails for an entire week and didn’t find anything, you still had to compensate him for his time. Even worse, if he did find something, made a pitch, and you didn’t get it, you were even further in the hole in terms of ROI. Still, I’ve gotten over 60 pieces of press through HARO over the years so I know it’s worth it. But I knew there had to be a better way.
I discovered MonkeyLearn: machine learning for dummies.
I’ve never tried to dabble in this field because it’s pretty technical and somewhat daunting. But now there are numerous artificial intelligence models in development that are based on a human actually showing a computer how to do something. The computer then reverse engineers the understanding and code to complete and improve upon those human actions.
There is a robotic chef https://www.youtube.com/watch?v=G6_LCwu7dOg
currently under development from Moley Robotics that uses computer vision to watch master chefs slicing, dicing, sautéing, stirring, etc…then it mimics those actions to complete recipes.
MonkeyLearn works the same way.
You “show” it any kind of data you want and then categorize each one and it will learn from it, constantly improving. This approach made complete sense to me since I’ve always been a visual learner. In fact the best way I’ve ever learned how to do anything physical, from skiing to hitting a golf ball, was to videotape myself doing it and then identify strengths and deficiencies.
A few typical uses of MonkeyLearn, for example, would be to do “Sentiment Analysis.” You could give MonkeyLearn a series of emails you’ve received and it tells you if the tone is angry or happy; very helpful for customer service tickets. You could also give it a series of car images and categorize them as Italian, German, French, or American and then let it go on from there. I thought I might be able to show it HARO queries and categorize them as Interesting or Not Interesting. The key here is that I couldn’t give you a set of parameters to clearly explain why one query might fit a particular category or another.
For example, if I saw a query for “Entrepreneurs who had Crohn’s Disease” from Men’s Health Magazine, I would certainly fit that description but an article in Men’s Health wouldn’t serve me from a business perspective, it would only stroke my ego. So I would categorize that as Not Interesting. But if a request came in that said “Chronic Illness and Time Management” from Entrepreneur Magazine I would categorize that as Interesting. So it’s not as simple as saying that I want to look for certain keywords or phrases.
The first step was to get the data into a form that MonkeyLearn could use. It’s very flexible. You can use Gmail messages, Facebook posts, RSS feeds, or just CSV files of data. Gmail might seem obvious but I didn’t want it to look at the email message as a whole, I wanted to drill down to each individual query. I ended up with methods; one is more accurate and takes a lot more time, the other is less accurate and takes a few minutes. You’ll have to decide for yourself.
The easy way is to use RSS and the few services in existence (such as HARO2RSS) that will provide an RSS feed of HARO items, for free, so you can grab those in a few clicks. The more advanced way is to use our old friend Zapier. Zapier has a built in service called, “email parser” where you can send it an email and then show it which parts of the email correspond to different types of data (much like machine learning). So you can forward a HARO email and highlight each query name and tell it to consider that part of all future emails. You can highlight the reporter’s email and call that contact email and so on. It’s tedious and you have to highlight each part of each query so that it will “scrape” that data in the future. The good news is you only have to do this the first time. Once it’s scraping data, Zapier can create its own RSS feed using RSS by Zapier, which you can then feed into MonkeyLearn.
Next comes the fun part, teaching MonkeyLearn what matters and what doesn’t. You can create a free account to get started and start to test. Plug in the RSS feed you’ve created or found, create your categories and then start categorizing those samples. They ask for a minimum of 40 but the more you supply, the better it will get. Also when you have categories that skew heavily (meaning there will be way more Not Interesting than Interesting) a larger sample size is better. Categorization looks like this…
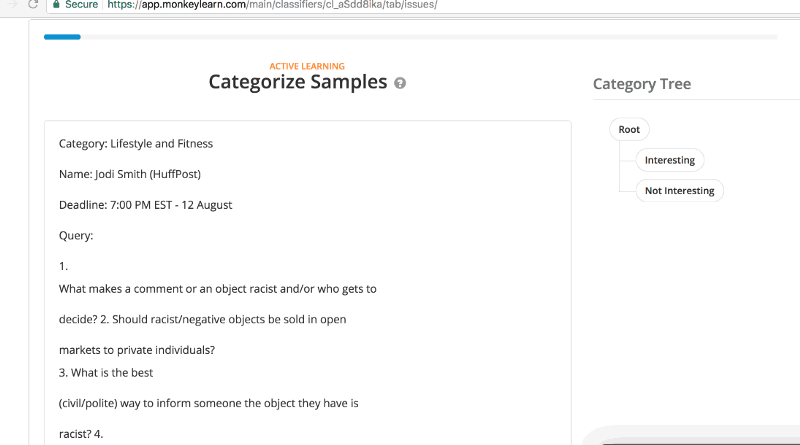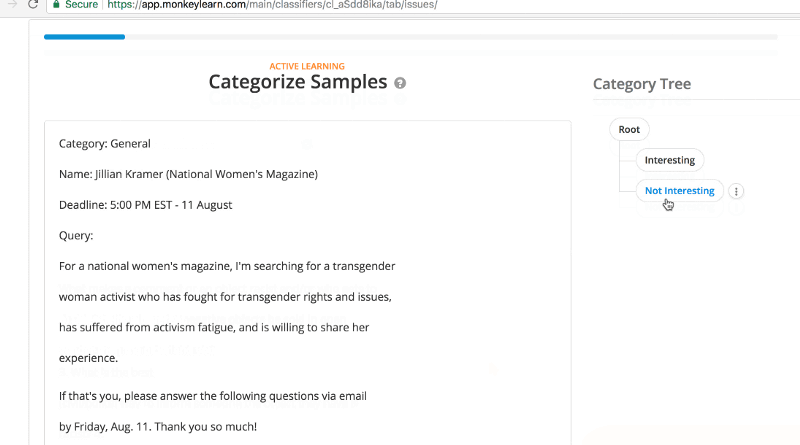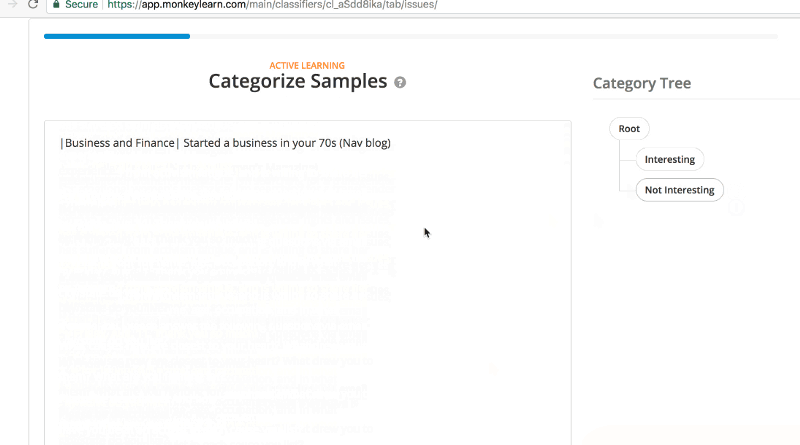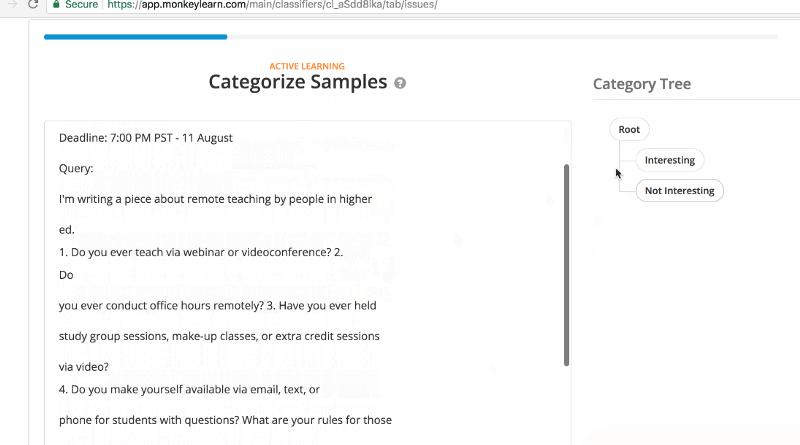
Once you go through a good number of samples, MonkeyLearn will have a sense of its accuracy. A mere 69 samples, resulted in a 87% accuracy rate for categorizing future samples. That was good enough for me.

Now what do you do with that information?
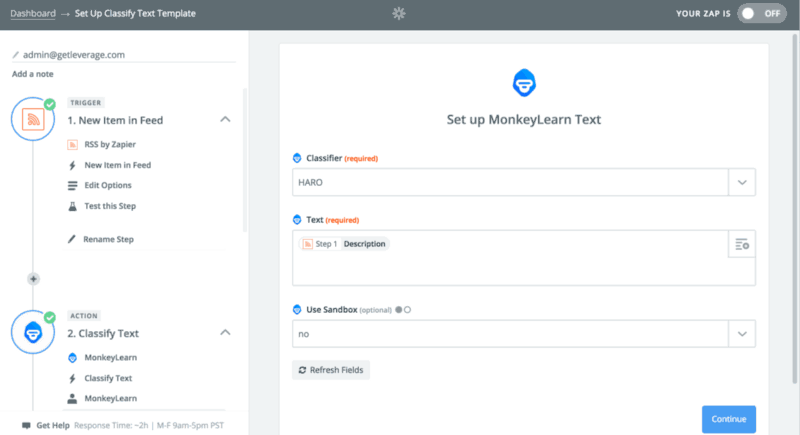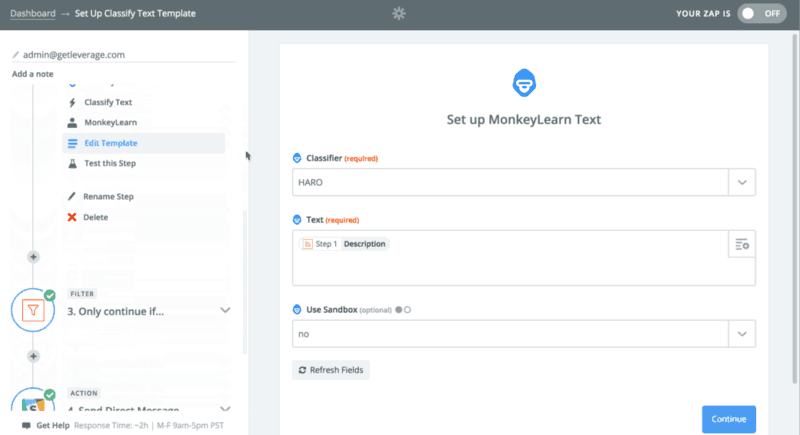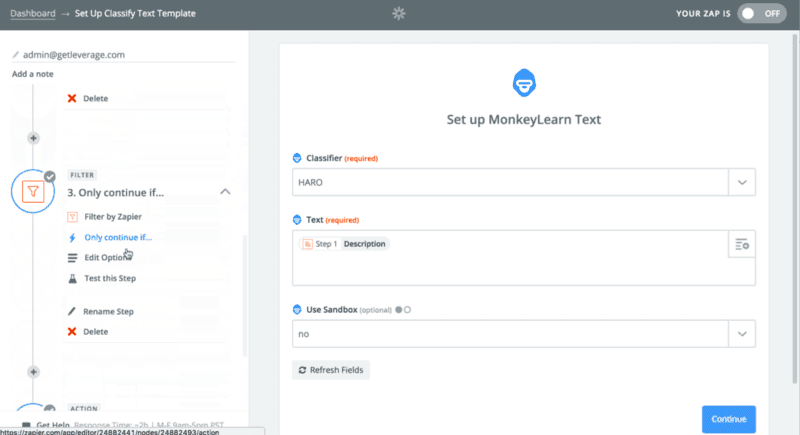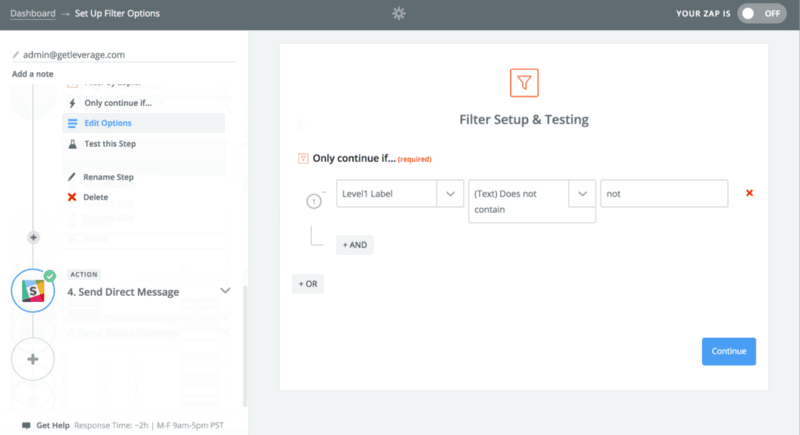
Let’s take a walk back over to Zapier. I had to setup a Zap that started with that same RSS feed we created or found. The trigger was any new RSS feed item. The first action was to have MonkeyLearn classify text that would spit out an Interesting or Not Interesting label. The next step was to build a Zapier filter which says only continue if the label does not contain “not” and deliver those results as a Slack direct message to me.
And the result is the occasional Slack message like this…YAHTZEE!

Now once or twice a week I get this type of message. It is invariably on point and worth pursuing. It’s difficult to contain my excitement about this process. It is a huge win and great use of technology that capitalizes on the platform’s capabilities and my input. It’s not just information that is now more accessible, but results as well.
The Next Level
If you really want to create a PR machine for yourself, you can actually automate the pitch to each of these queries. You would simply add another filter to the zap and include a gmail message step to finish it off. So you could say, once an interesting query is delivered, if that query mentions entrepreneurs, you could automatically send a gmail message with a standard pitch about your entrepreneurial journey. The result is a free, automated, publicist in a box. Sweet, right?https://upscri.be/6892b4?as_embed=true
Whenever you are ready…here are 4 ways I can help you become more replaceable and grow your business:
1) Join our FREE Facebook Group — The Replaceable Founder
2) Get our FREE Replaceable Founder Mini-Course
3) Come to our next One-Day Intensive “Becoming Replaceable Workshop” in NYC
4) Want to work with us privately? Just answer a few questions and find out if you’re a good fit. Apply Now
